Implicit neural fields have made remarkable progress in reconstructing 3D surfaces from multiple images; however, they encounter challenges when it comes to separating individual objects within a scene. Previous work has attempted to tackle this problem by introducing a framework to train separate signed distance fields (SDFs) simultaneously for each of N objects and using a regularization term to prevent objects from overlapping. However, all of these methods require segmentation masks to be provided, which are not always readily available.
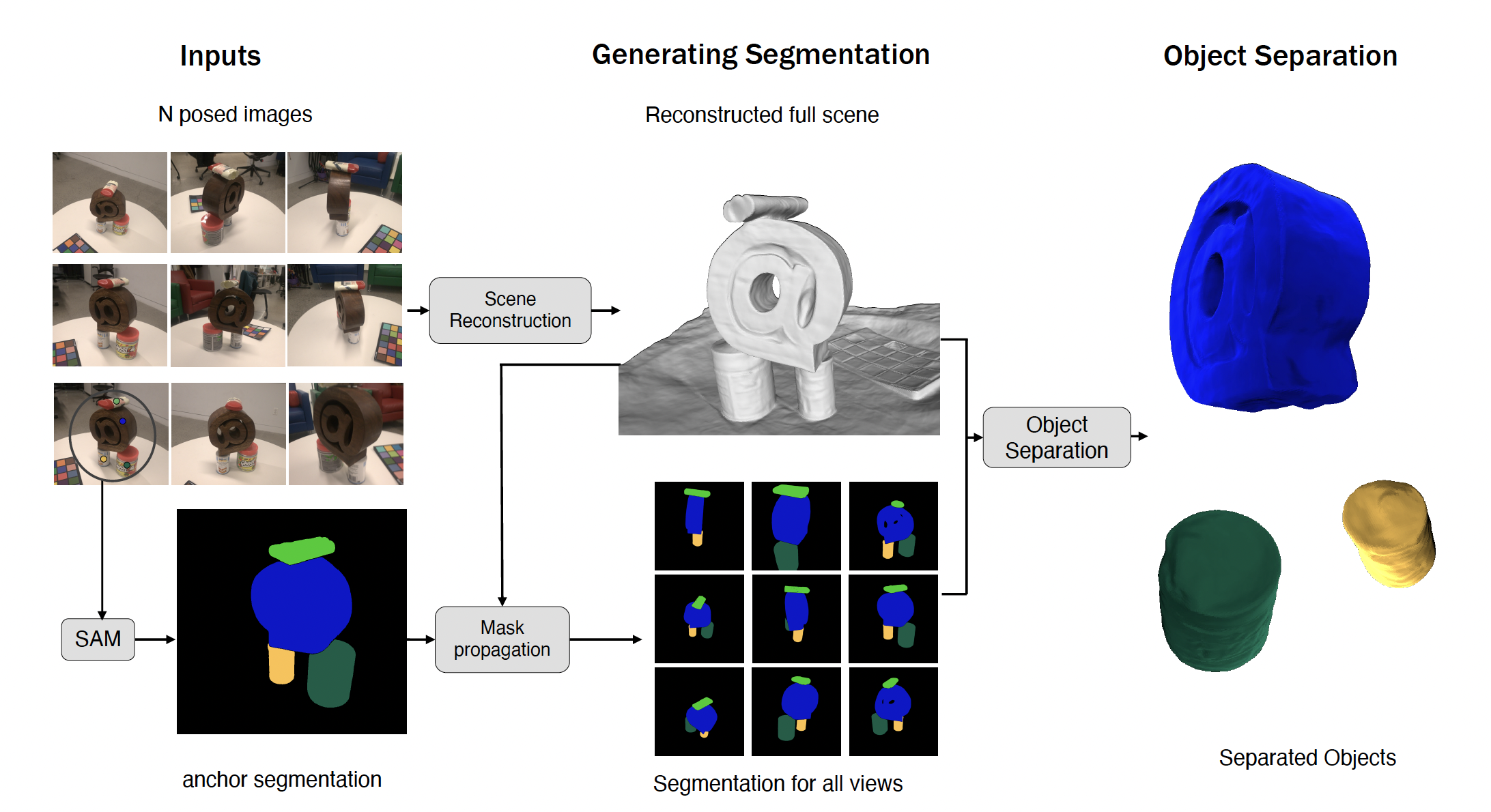
We introduce our method, ObjectCarver, to tackle the problem of object separation from just click input in a single view. Given posed multi-view images and a set of user-input clicks to prompt segmentation of the individual objects, our method decomposes the scene into separate objects and reconstructs a high-quality 3D surface for each one. We introduce a loss function that prevents floaters and avoids inappropriate carving-out due to occlusion.
In addition, we introduce a novel scene initialization method that significantly speeds up the process while preserving geometric details compared to previous approaches. Despite requiring neither ground truth masks nor monocular cues, our method outperforms baselines both qualitatively and quantitatively. In addition, we introduce a new benchmark dataset for evaluation.
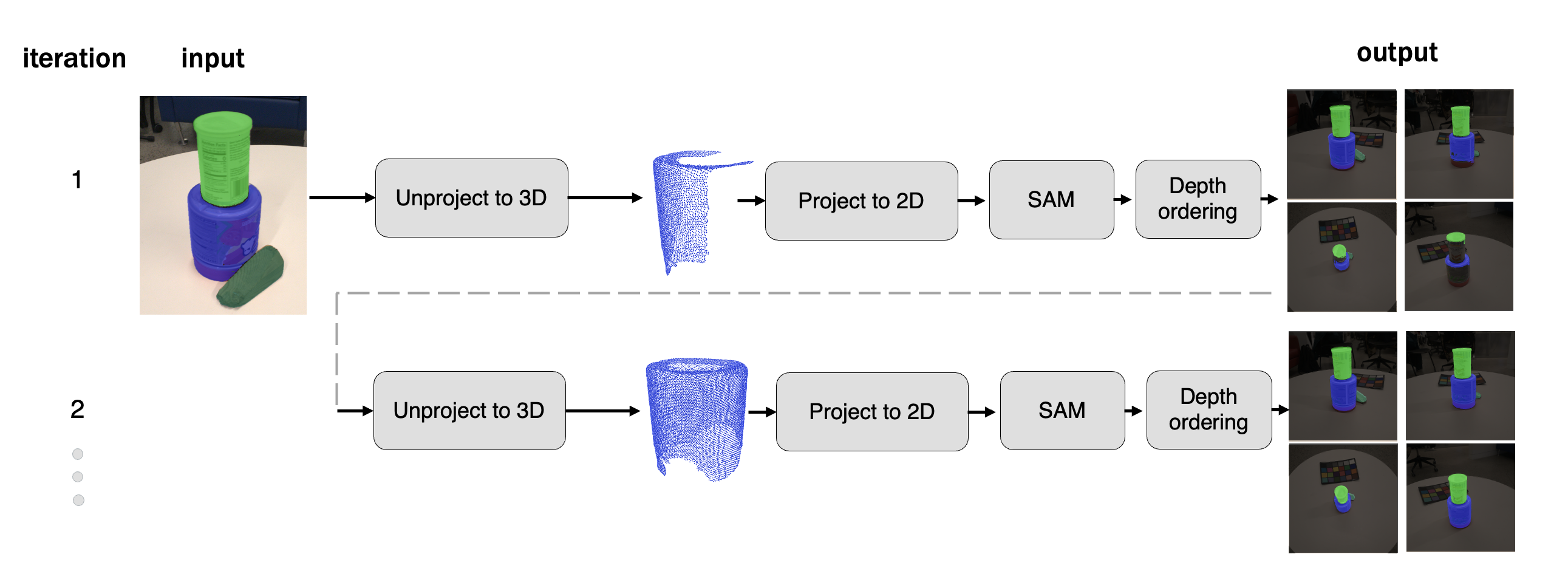
We propose a mask generation technique that generates segmentation masks for all the input views from just user clicks in one input view.. in the first iteration, a user clicks a point on each object to generate a per-object anchor mask, which are then unprojected into 3D (here, we only show unprojected 3D points for the bottom can). These 3D points are subsequently projected back into each image view, while checking for occlusions. The projected points serve as seeds for SAM to generate masks for each object (bottom and top cans, door stop). To combine these individual segmentation masks into a single image, we use a depth ordering technique. In the next iterations, all views are used as anchor masks, allowing the pipeline to cover previously unseen regions.

Previous scene decomposition techniques evaluate their methods on benchmark datasets like Replica and ScanNet. A critical limitation of these is that they do not offer complete ground truth geometries for the reconstructed objects. We introduce a new benchmark for 3D scene decomposition techniques, consisting of 30 real-world scenes and 5 synthetically generated ones. The scenes contains different combinations of objects in close contact, and we provide a high-quality complete mesh of each object. We show samples of the captured real-world scene and scanned individual meshes, with the captured scene displayed below this paragraph and the scanned meshes above.


@article{hassena2024objectcarver,
title={ObjectCarver: Semi-automatic segmentation, reconstruction and separation of 3D objects},
author={Hassena, Gemmechu and Moon, Jonathan and Fujii, Ryan and Yuen, Andrew and Snavely, Noah and Marschner, Steve and Hariharan, Bharath},
journal={arXiv preprint arXiv:2407.19108},
year={2024}
}